BurpAuthTest 越权检测插件
0x00
最近一段时间,做了一些自动化/半自动化的测试小工具,主要还是想从重复的工作中解放出来,把时间投入到更有意义的事情中。
开发语言也从之前的 Python 逐步切换到了 Rust,虽然 Python 是一门很棒的语言,可以让我快速的实现各种想法的原型,但是 Python 在工程化的时候,总会出现一些不尽人意的地方。恰巧之前也学过一些 Rust,便逐步将主力开发语言切换到了 Rust。关于这部分的内容,后续可以再单独讲讲。
在最近的一些测试工作中,很大一部分目标都是各类 CMS、WMS 系统,经过前期的一些人工测试,发现这类业务逻辑相对简单且以 CURD 为主的系统,很难出现一些高危的 Web 漏洞(特指常见高危Web漏洞,例如:命令执行、SSRF、SQL注入等)。主要的风险还是以水平越权和垂直越权为主。
很多人可能根据经验会有疑问,为什么很少甚至不会出现 SQL注入漏洞?
在大型甲方企业的开发流程中,开发这类系统时,一般都不是从零开始写第一行代码的,而是使用该团队积累下来的各种二方包。对于常见的业务操作,例如 CURD、OSS上传等等,都有较为成熟的框架和解决方案。一旦出现过一次漏洞,通过对二方包的修复,很容易就实现了对所有其他系统的修复,以及在新系统中的预防。
顺便一提,对于其他类型的漏洞,例如 SSRF 和 命令注入等,在常规的 CURD 类的 CMS、WMS 系统中,根本不会出现相关的业务场景,所以更不会出现相关的漏洞了。
越权检测一直是扫描器领域长盛不衰的话题,目前在越权检测这个方向下面,还没有看到非常成熟的方案,也没有通用的银弹。
虽然没有银弹,但是一定有人已经造过轮子了,先去搜索了一些 Burp 上比较知名的越权测试插件,使用了一圈下来感觉都很不爽。有些界面丑陋且已经年久失修无法使用,有些逻辑复杂操作反人类,终于还是决定写一个自己用起来顺手的小插件。
0x01
在正式开始造轮子之前,我们先回顾一下手动测试越权的流程。
假设我们使用两个相同权限的账号 A 和 B,分别使用不同的浏览器登录。Chrome 登录账号 A,Edge 登录账号 B,给 Chrome 浏览器添加代理,把流量转发到 Burp。
在 Burp 中发现一个接口:http://api.example.com/user/get?id=10001 ,分析后发现是查看当前用户信息的接口。此时如果想测试越权,我们需要找到账号 B 中,此接口对应的参数,并将其复制过来到 Burp 中。假设 B 账号得到的参数为 id=51234 ,在 Burp 中修改参数后发送,并人工检查 Response 中是否含有 B 账号的数据。
在这个过程中需要来回切换多个窗口,复制粘贴不同账号的数据,最后还需要人工对比 Response 数据的内容,需要操作很多个步骤,并且非常的麻烦。另外这只是进行了两个同权账号的测试,如果系统的角色非常复杂,有管理员、普通会员、子账号的情况下,需要手工处理的工作就更多了。
测着测着,很自然的就出现了第二个想法:如果不替换参数,直接替换身份凭证是否可行?
答案自然是可行的,我们不用再去复制 B 账号每个接口的参数,只需要登录一次 B 账号并获取到 B 账号的身份凭证信息(Cookie、X-ACCESS-TOKEN等),在每次测试 A 账号的时候,顺手把 A 账号的身份凭证修改为 B 账号,就相当于以 B 账号的身份使用 A 账号的参数发起请求,直接查看返回是否一致就可以了。我们不需要来回的切换窗口,完全在 Burp 一个窗口中操作就可以了,当 Response 过大不方便肉眼看的时候,甚至可以使用的 Burp 的 diff 功能检查两个包是否有相同数据。
当然这个方案也有弊端:
- 如果参数中、头中含有 CSRF Token 或类似的标记,此方法无法通过服务端的相关校验;
- 依然无法避免角色过多带来的重复操作问题,同一个接口,每一个角色都要替换数据发一次包;
- 在少部分业务场景下,如果参数本身是无规则字符串,例如 UUID、MD5 等情况且根本没有接口可以获取到其他账号的资源 ID,按照业务设计规则,可能不涉及越权问题;
- 这一点实际上是有分歧的,理论上来说,我使用其他账号的资源 ID 获取到了资源内容,本身就属于越权,只能最终与业务沟通并根据实际情况再做是否修复的决定。
到目前为止,我们有了一些进展,简化了替换参数的工作量。但是我仍然希望将这个过程自动化,在我每次测试其他漏洞的时候,Burp 自动化帮我替换身份凭证,并比对返回值是否相似。
0x02
我们首先要解决的问题,就是账号的替换的问题,对同一个接口的请求,要以何种策略进行重放,是这个插件的核心逻辑。
回顾一下正常的测试流程,为了测试水平越权和垂直越权,我们至少需要准备3个账号,如果我们只想测试水平越权,或只想测试垂直越权,那么准备两个账号就可以了:
- A 类账号:基准账号;
- B 类账号:同权账号,与 A 类账号同权限,用于测试水平越权;
- C 类账号:低权、无权账号,比 A 类账号权限低,用于测试垂直越权;
有了账号,下一步需要确认的就是重放顺序。对于查询数据的请求而言,重放顺序并不那么重要,无论哪个账号先执行请求,都不会影响返回结果。而对于创建资源、修改资源、删除资源之类的请求,顺序就非常敏感了。比如针对一个删除操作的越权测试,如果我们先使用 A 类基准账号测试,那么无论是否有漏洞,C 类账号的操作一定是失败的,因为资源已经被删除了,也就没办法使用这个资源 ID 进行越权测试了。如果使用 B 类同权账号进行测试,假设存在水平越权漏洞,那么资源已经被 B 类账号删除,C 类账号操作也会失败,也无法判断是否存在垂直越权了。
根据以上推论,我们可以规定出请求重放的顺序:C 类账号 > B 类账号 > A 类账号,在每次请求完成后,把响应结果记录下来,当所有的重放完成后,对响应内容进行相似度判断以检查是否存在越权漏洞。
现在看起来似乎没有什么问题了,但是我们还忽略了前面提到的一点,如果业务系统有更多的角色或者业务身份呢?比如超级管理员,小管理员,后台管理员,前台管理员,普通会员,游客等等。
首先我们先看看能否简化为ABC三类账号,比如有些系统虽然有很多角色,但是是通过为某个账号单独赋权得到的。举个例子,某个系统的账号必须归属于其中的一个角色,而每个角色类型可以单独设置权限点。虽然看起来这个系统非常复杂,有非常多的角色,但是实际上我们测试时,只需要一个开启所有权限点的角色,和一个没有任何权限点的角色。两个开启全部权限点的角色的账号分别作为 A 类账号和 B 类账号,没有权限点的角色可以作为 C 类账号,问题迎刃而解。
但是实际测试中发现,并不是所有的系统都可以这样处理,有些系统无论如何也无法简化为 ABC 三类账号,那又要怎么办?
此时我们只需要对插件的账号系统做一些小小的修改即可,添加一个 D 类账号,代表自定义角色。那么问题又来了,D 类账号的重放顺序应该如何定义呢?很明显当你遇到这么复杂的情况时,事先并不能确定应当如何重放,也就无法在插件中写死重放顺序,添加一个优先级功能根据实际情况判断是最好的做法了。
那么现在的账号体系就变成了下表这样,优先级越高请求顺序越靠前:
- A类账号,优先级-1,基准账号,所有其他账号的 Response 均和这个做对比,优先级最低,一定最后一个重放请求;
- B类账号,优先级50,同权账号,用于测试水平越权,优先级默认为 50,夹在低权和基准之间;
- C类账号,优先级101,低权账号,用于测试垂直越权,一定第一个重放请求;
- D类账号,优先级1~100,自定义角色,请求优先级可以根据实际情况自定义;
最后,再添加一个配置管理系统,给不同的站配置不同的账号,再加一点点界面,基本上就完成了。
0x03
每一个配置相当于一次测试项目,在同一时间,只能开启一个配置。
在每一份配置中,可以单独配置目标 scope、黑名单、重放设置等,防止触发重放各种不必要的请求;
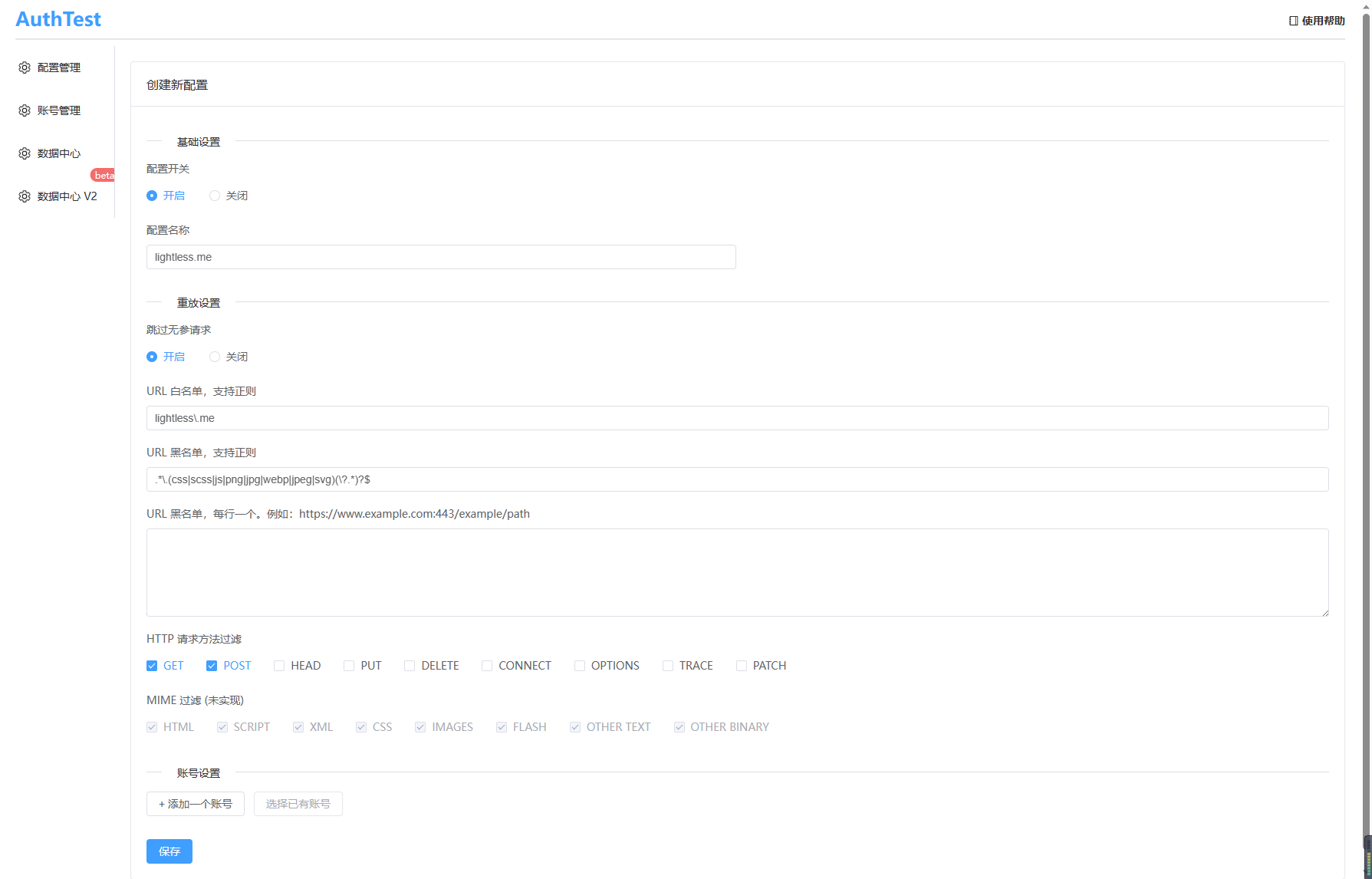
同时账号也是在每一份配置中设置的,在这里填入需要替换的身份凭证信息,可以是 HTTP Header,也可以是某个参数。
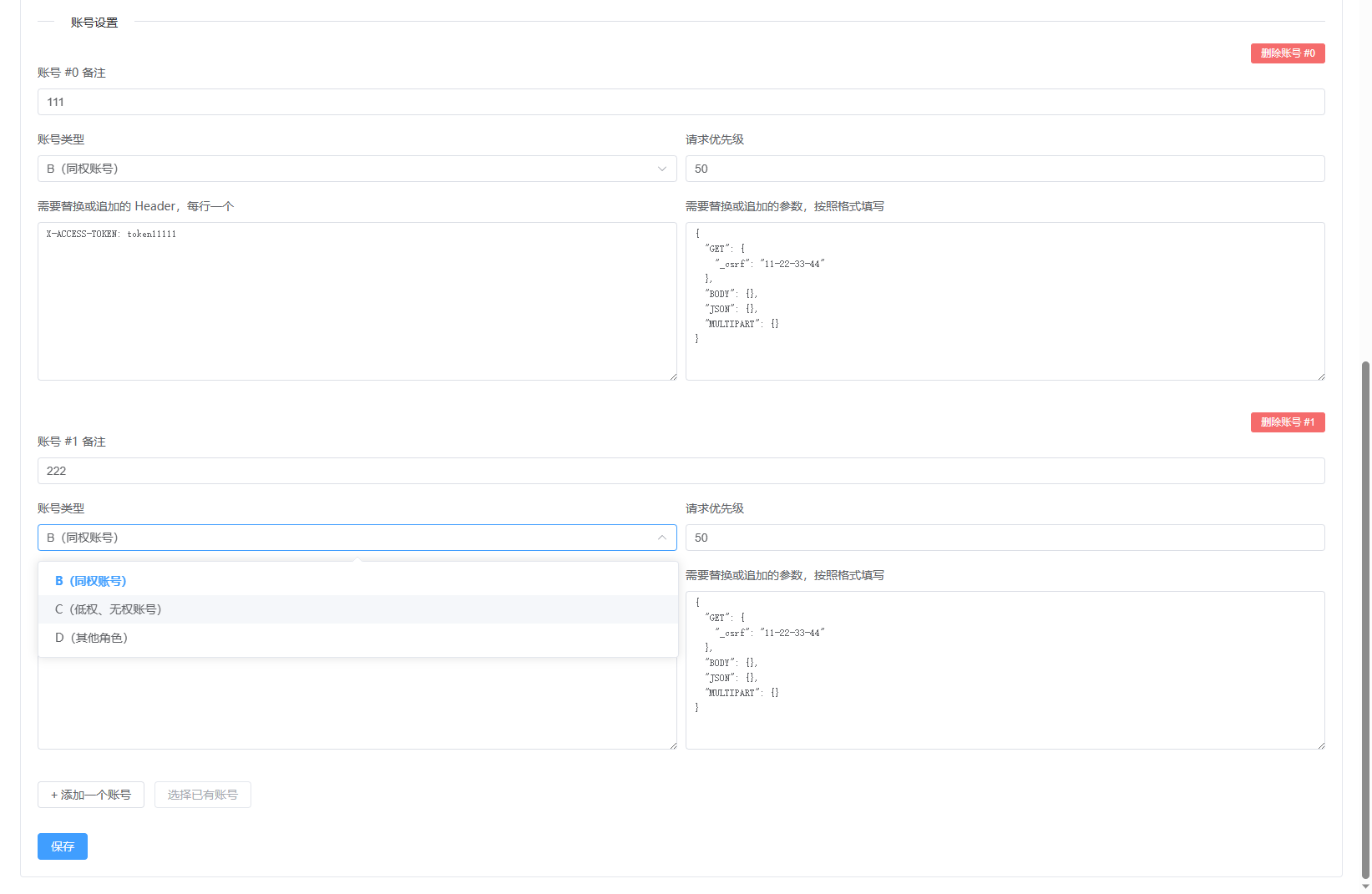
当正确配置完成账号信息后,此时在浏览器中访问目标网站,AuthTest 将会使用配置好的账号自动重放这些请求。所有的请求都会在数据中心中展示。
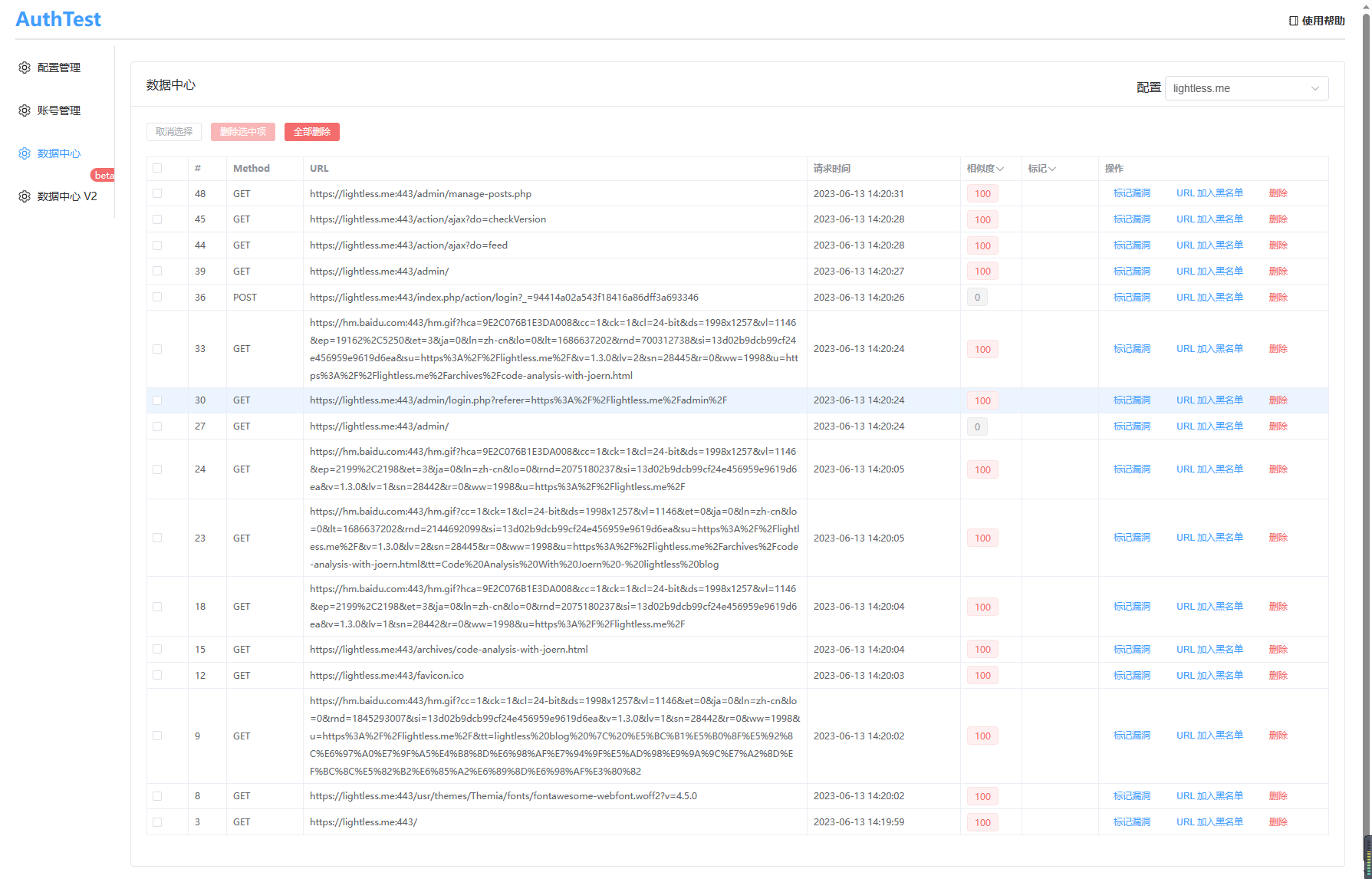
在这里,可以对某些请求标记为漏洞,也可以将某些请求加入黑名单(比如图中出现的baidu统计请求),加入黑名单后,后续遇到该 URL 时将不再重放。
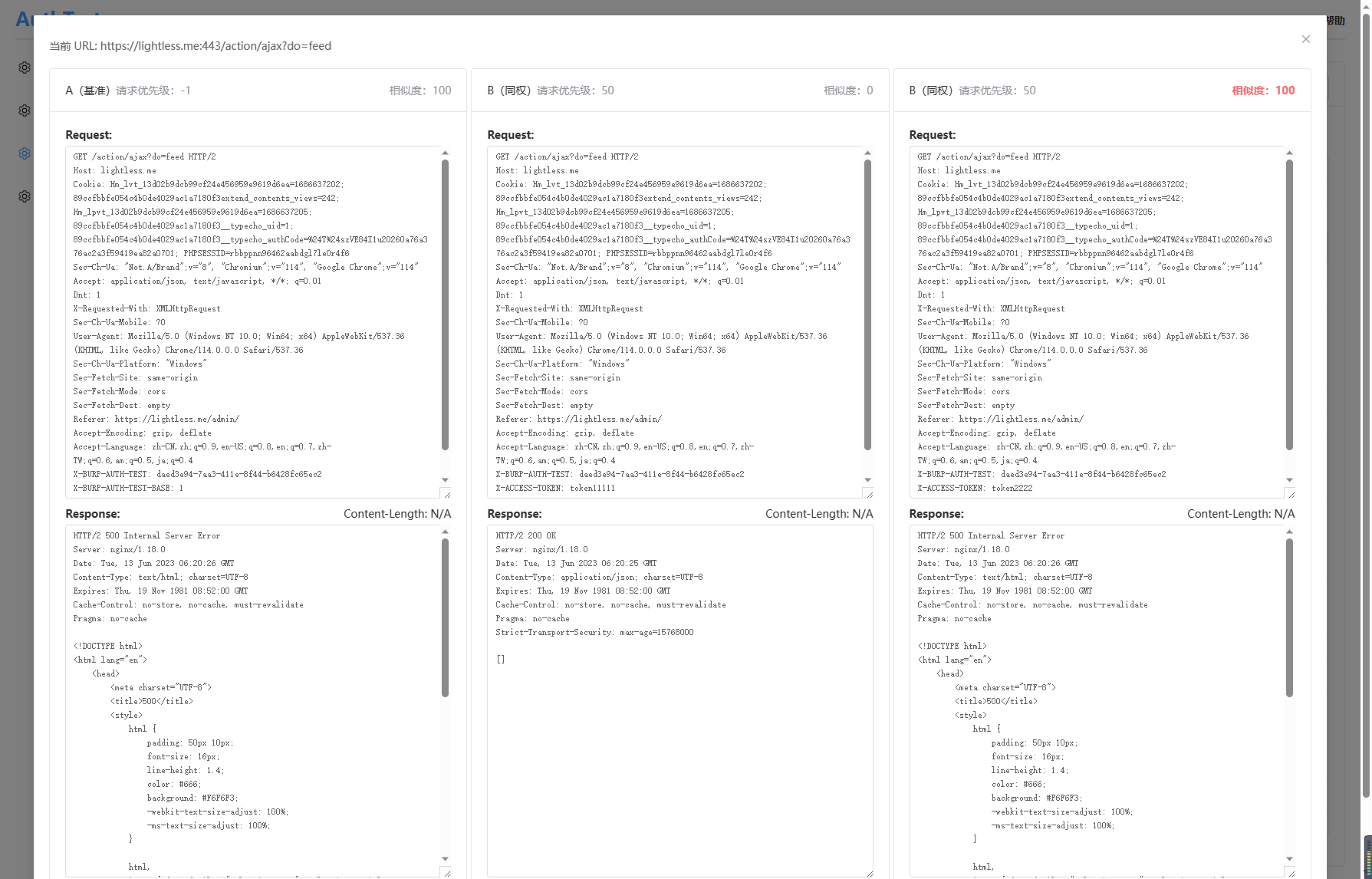
点击某一行即可看到详细的请求信息,相似度为每一个包与基准账号的 Response 做对比,使用了编辑距离算法。
经过一些实际测试,确实解放了工作中很大一部分的劳动力,减少了很多的重复性工作,漏洞挖掘效率也得到了显著提升。
不过由于该工具还在完善阶段,并且很多功能是针对个人使用习惯高度定制化的,暂时没有开源的打算,后续也会继续分享一些最近一段时间开发的其他小工具,以及一些安全建设理念。等到小工具打磨成熟了,会适时的放出来与大家一起使用。

不错的思路,也这么想过,不过动手能力太差,只能等后期大佬分享了。。。
大佬,我这里有个问题想请教一下,对于你提到的删除接口越权的检测,如果我配置了资源外的水平权限账号B,那么按照你说的顺序会先用B的凭证重放请求,再重放A的。那么这里假设越权删除存在,B的请求会返回成功,A会返回失败,那么看起来这是两个请求是不一样的,跟原有的越权检测逻辑是不一样的,这里需要怎么从结果中区分呢? 希望大佬指点一二!
这种需要分情况看,有些网站的删除接口,无论删除的资源是否存在,都会返回成功。而有些网站则会像你说的一样,真删掉的时候返回成功,没资源的时候返回失败。
所以这个插件也只是个半自动化的工具,是否存在越权没办法完全自动判断,还需要人工介入。
这套BurpAuthTest越权监测的系统请闻还有再做麼?
这个插件开源了吗?